Static data
Created 2006-10-21T06:29:27.736Z, last edited 2007-04-18T15:51:54.927Z
This database schema is not intended to be optimised for any of:
- database size;
- data access speed;
- or data input speed.
So what is it going to be optimised for?
Most importantly I want to make the design clear and simple. Coming up with ways to calculate prospective scores for customers is going to be plenty hard enough so I don't also want to be dealing with complex data structures. Optimising for design clarity and implementation simplicity first and foremost doesn't mean that I'm going to completely ignore the other issues, but I'm not putting them first.
By building a fairly standard FOST.3™ database schema not only keeps it simple, but I get some extra advantages too. The most important of which is that I have to write almost zero code to get it working. In fact I'll be able to examine the data structures and even populate them through a web interface without having to do anything more than compile the UML into SQL and C++ and recompile the C++ into a DLL.
Secondly I get to use Javascript to test out ideas. The FOST.3™ UML compiler will generate a COM layer to go with the C++ code. This means that I can handle heavier weight algorithms by writing them in C++, but I can test ideas out more quickly by using a scripting language. I can also do some parts of the calculations as SQL where that is the easiest to formulate.
The schema
The schema from the point of view of the customers, movies and scores is pretty simple (click on the diagram for a better look and an explanation of the notation).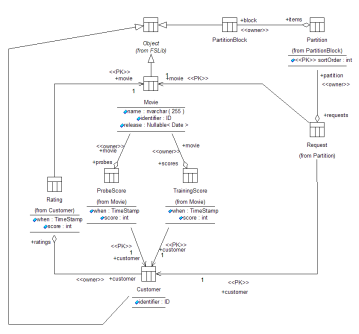
The schema for the static data calls for both the movies and the customers to be full blown objects. This imposes an overhead in their creation, but the numbers show that the extra SQL statements required to create these in comparison to the SQL statements needed to manage the ratings is still pretty low — remember that there are over 100 million ratings (including the probe and qualifying sets) and less than 500,000 customers and movies. The way that the object/relational mapping works in FOST.3™ means that immediate sub-classes of Object require two SQL INSERT statements to add to the database. This means that the number of SQL statements required to add them to the system will be less than one million.
Movies
The customers and films are the two most obvious data groupings. The probe data is supplied mixed in with the training data and one obvious design is to do exactly the same thing, but set a flag for the probe data.
For many applications it is a good approach, but it does have one serious drawback. Any bug in the scoring algorithms may mean that they mix these two data sets up. This may invalidate our findings or skew our results. It's also going to be very difficult to notice. Mostly because of this I felt that it would be much better to separate the probe and training data within the design. This means that any algorithm can look across all of the training data without needing to check a flag.
If you're stuck with a less capable implementation (for example doing all the SQL by hand) then the cost of each table in the database will be high for initial development, but the extra flag column cheap. Choosing the cheap option up front seems reasonable until you also factor in the cost of making sure that the flag is correctly set and read for each and every access to the scoring data.
With a good object/relational mapping system like FOST.3™ this cost differential becomes a moot point as the extra table and the extra column have the same up-front cost and the extra table has the lower on-going development cost.
Customers
The full set of customers can only be read implicitly from the ratings that they have made. We know nothing about how the customers IDs have been issued. When writing software to deal with the customers it's going to be very convenient to be able to fetch the films the customer has rated without having to go through the films and search for them. This is clearly a win in terms of simplicity of programming, but the design makes it look like we need to duplicate all of the ratings information — and at nearly 100,000,000 ratings that's a lot of data to duplicate.
It turns out though that we can use an SQL view in order to implement this efficiently without using any extra database storage. Better yet, it will amount to automatically adding a rating to the correct film if we add it to a customer and it will automatically add it to a customer if we add it to film. Even better yet the optimisation is done in such a way that we don't need to even let the C++, COM or any other code layer know that we've done it — the database handles it all for us.
Here are the SQL statements that the UML compiler uses to create the two tables in question:
| Netflix_Movie_TrainingScore | Netflix_Customer_Score |
|---|---|
CREATE TABLE [Netflix_Movie_TrainingScore] ( [customer_id] int NOT NULL, [movie_id] int NOT NULL, [score] int NOT NULL, [when] char ( 23 ) NOT NULL, CONSTRAINT [PK_Netflix_Movie_TrainingScore] PRIMARY KEY ( [customer_id], [movie_id] ) ) |
CREATE TABLE [Netflix_Customer_Rating] ( [customer_id] int NOT NULL, [movie_id] int NOT NULL, [score] int NOT NULL, [when] char ( 23 ) NOT NULL, CONSTRAINT [PK_Netflix_Customer_Rating] PRIMARY KEY ( [customer_id], [movie_id] ) ) |
You may not notice a whole load of difference here. One reason for this is that the UML compiler has actually produced the wrong code (which I'm going to have to fix). The correct code it should have produced is this:
| Netflix_Movie_TrainingScore | Netflix_Customer_Score |
|---|---|
CREATE TABLE [Netflix_Movie_TrainingScore] ( [customer_id] int NOT NULL, [movie_id] int NOT NULL, [score] int NOT NULL, [when] char ( 23 ) NOT NULL, CONSTRAINT [PK_Netflix_Movie_TrainingScore] PRIMARY KEY ( [movie_id], [customer_id] ) ) |
CREATE TABLE [Netflix_Customer_Rating] ( [customer_id] int NOT NULL, [movie_id] int NOT NULL, [score] int NOT NULL, [when] char ( 23 ) NOT NULL, CONSTRAINT [PK_Netflix_Customer_Rating] PRIMARY KEY ( [customer_id], [movie_id] ) ) |
As we know that the training scores for a film will always be requested based on the film we know the film ID needs to be first in the primary key1.
Any change in column order within the table isn't really significant, but the difference in column order on the primary key is as this will directly impact performance. I took the Netflix_Movie_TrainingScore as my base table. Using this I can add a unique index reversing the primary key order and create an index together with a view like this:
CREATE UNIQUE INDEX UQ_Netflix_Customer_Score
ON Netflix_Movie_TrainingScore
( customer_id ASC, movie_id ASC )</pre>
<pre>CREATE VIEW Netflix_Customer_Rating AS
SELECT
customer_id,
movie_id,
score,
[when]
FROM Netflix_Movie_TrainingScore
This is where the features you have available on your RDBMS becomes critical. The SQL standard says that you should be able to insert into a view and everything should work. This means that the following statements will both populate the underlying Netflix_Movie_TrainingScore.
INSERT INTO Netflix_Movie_TrainingScore
SELECT 123, 4, 3, '2006-10-31 11:13:00.000'
INSERT INTO Netflix_Customer_Rating
SELECT 5, 123, 4, '2006-10-31 11:13:15.000'
Running them produces the following result:
| Netflix_Movie_TrainingScore | Netflix_Customer_Score | ||||||
|---|---|---|---|---|---|---|---|
| movie_id | customer_id | score | when | customer_id | movie_id | score | when |
| 123 | 4 | 3 | 2006-10-31 11:13:00.000 | 4 | 123 | 3 | 2006-10-31 11:13:00.000 |
| 123 | 5 | 4 | 2006-10-31 11:13:15.000 | 5 | 123 | 4 | 2006-10-31 11:13:15.000 |
What it means is that:
- At the application level we have a choice as to whether we populate the view or the table.
- The two tables will be guaranteed to be in perfect synch.
- We don't waste several gigabytes of disk space storing the same data in a slightly different representation.
Anybody who tells you that you don't need views is right. Anybody who also tries to tell you that they're not useful doesn't know what they're talking about. It's clearly possible to add several more gigabytes to the database, or always have to manage the SQL to use the data as connected to the films.
It's also clearly better to have a simple design which appropriately appears to duplicate data to make our lives as data consumers and maintainers easier.
Partitions
The final part of the static data are the movie ratings that the algorithms have to generate. The classes PartitionBlock, Partition and Request are intended to drive the algorithms in terms of which results to supply (and in which order). The partitions do three things for us:
- Allow us to store the question that we're being asked. We want to be able to store the questions for both the probe and qualifying sets.
- Provide a way to drive the algorithms to produce the answers we want. We want to be able to parallelise the answering of a large question set into small chunks (I'm calling each chunk a partition).
- Allow us to define small sub-sets of a data set in order to be able to test, debug and measure the performance of the algorithms.
We'll fully explore the partitions as we move on to the actual algorithms. The base partitions that handle the probe and qualifying data sets will be part of the static import process along with the rest of the data we've looked at here. Splitting up the partitions further for testing and debugging will be looked at seperately.
Sub-pages




© 2002-2025 Kirit & Tai Sælensminde. All forum posts are copyright their respective authors.
Licensed under a Creative Commons License. Non-commercial use is fine so long as you provide attribution.