Implementing a state engine using instance behaviour
Created 2006-10-19T12:03:19.014Z, last edited 2007-12-11T01:48:17.687Z
State engines are a pretty useful, but underutilised programming technique. Most common ways of implementing them tend to give pretty messy code.
Part of the problem is of course the impedance mismatch between the programming languages we use and the state engine. Even in object oriented languages we normally see state engines implemented in terms of a switch statement which grows to gargantuan proportions.
What I'm going to do is to show how to neaten these implementations up by making use of an advanced object-oriented technique called instance behaviour.
An attribute parser
State engines are often useful ways of implementing parsers, so for my example I'm going to write an attribute parser that would be useful for HTML or XML documents. What we want to be able to parse are the attribute strings that sit within the elements:
<html>
<head><title>My page</title>
<link rel="stylesheet" type="text/css" href="/style.css">
<link type="alternate feed" href="/atom.xml">
</head><body>
<h1 class="first">My heading</h1>
<p class="first" align="center">Probably the worst HTML example in the world</p>
</body>
It's clearly not a great bit of HTML, but it does show some typical sorts of attribute values. All we're going to process are these parts:
rel=“stylesheet” type=“text/css” href=“/style.css” type=“alternate feed” href=“/atom.xml” class=“first” class=“first” align=“center”
And produce a collection of name, value tuples (where value can be null) which we can process in some way later on.
The state engine
The parser shown in the state diagram to the right isn't expected to handle every error condition and nor does it enforce rules about which characters are legal within things like attribute names. It's really a very minimal starting point, but will illustrate the difference in the two approaches.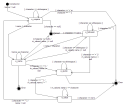
I'm going to implement the parser in Javascript because it allows a fairly simple implementation of both techniques without too much syntactic overhead.
The form I'll use is a single function that will create a parser object to perform the work and then pull the result out from that parser object. Because Javascript supports local functions we can do this all fairly simply and as a single self-contained function.
switch statement implementation
The code below is the basics of the implementation using a switch statement to handle the differing actions depending on the current state. Note that I only show the code for one state.
function parseAttributes( toparse ) {
function Parser( string ) {
this.e_wspace = 1; this.e_name = 2; this.e_between = 3; this.e_quote = 4; this.e_value = 5; this.e_parsed = 6;
this.doCharacter = function( character ) {
switch ( this.state ) {
case this.e_wspace:
if ( character == null )
this.state = this.e_parsed;
else if ( isWhitespace( character ) )
;
else if ( character == '=' || character == '"' )
throw "Error - Unexpected '=' or quote";
else {
this.state = this.e_name;
this.name = character;
}
break;
// Other cases cut for brevity
}
this.attributes = new Array();
// Transition from Constructor to e_wspace
this.name = null;
this.state = this.e_wspace;
// Go through characters feeding them one at a time with a final null
for ( var p = 0; p < string.length; ++p )
this.doCharacter( string.charAt( p ) );
this.doCharacter( null );
if ( this.state != this.e_parsed )
throw "Error - end state should be e_parsed";
}
return new Parser( toparse ).attributes;
}
Javascript doesn't have any way to implement the enumeration for the states cleanly, but I'm not going to hold that against the implementation. As for the rest of it, with just a handful of states and fairly simple behaviour for each state this isn't too complex.
The function doCharacter() is the heart of the implementation. We can easily see how we could extend this to include new states — we add a new member to the enumeration for the state and add a clause to the switch statement. Not exactly DRY, but not too wet either.
I won't dwell any longer on this implementation because it is probably familiar to most of us.
Instance behaviour implementation
In this version we're going to make use of the fact that Javascript is able to manipulate functions as first order objects. What this means is that we will assign a function for each state within our Parser class.
Here is the code for the e_wspace state:
this.e_wspace = function( character ) {
if ( character == null )
this.state = this.e_parsed;
else if ( isWhitespace( character ) )
;
else if ( character == '=' || character == '"' )
throw "Error - Unexpected '=' or quote";
else {
this.state = this.e_name;
this.name = character;
}
}
The meat of the implementation is the same, but the presentation is different. Note though that e_wspace rather than being some arbitrary value it is now the actual code that is to be executed for that state.
Storing the current state looks exactly the same. Here is the transition within the constructor to the first state:
this.name = null;
this.state = this.e_wspace;
This is identical. We are still storing the current state within the this.state and we can still check that we end on the correct end state in exactly the same way:
if ( this.state != this.e_parsed )
throw "Error - end state should be e_parsed";
But the way that we make use of it is different. this.state now is the code to execute so when we go through the string we simply execute the state:
for ( var p = 0; p < string.length; ++p )
this.state( string.charAt( p ) );
this.state( null );
And this of course is the core of the technique. Rather than using a swtich statement to deliver our “process this character” message to the correct code we can now use the core language facilities directly.
This is certainly more elegant, and although the code that executes for each state is identical the separation out into separate functions still helps us to better understand it.
Here is the full implementation with all states:
function parseAttributes( toparse ) {
function Parser( string ) {
this.e_wspace = function( character ) {
if ( character == null )
this.state = this.e_parsed;
else if ( isWhitespace( character ) )
;
else if ( character == '=' || character == '"' )
throw "Error - Unexpected '=' or quote";
else {
this.state = this.e_name;
this.name = character;
}
}
this.e_name = function( character ) {
if ( character == null ) {
this.attributes.push( [ this.name, null ] );
this.state = this.e_parsed;
} else if ( isWhitespace( character ) ) {
this.attributes.push( [ this.name, null ] );
this.state = this.e_between;
} else if ( character == '"' )
throw "Error - Unexpected quote";
else if ( character == '=' ) {
this.attributes.push( [ this.name, null ] );
this.state = this.e_quote;
} else
this.name += character;
}
this.e_between = function( character ) {
if ( character == null )
this.state = this.e_parsed;
else if ( isWhitespace( character ) )
;
else if ( character == '"' )
throw "Error - Unexpected quote";
else if ( character == '=' )
this.state = this.e_quote;
else {
this.state = this.e_name;
this.name = character;
}
}
this.e_quote = function( character ) {
if ( isWhitespace( character ) )
;
else if ( character == '"' ) {
this.attributes[ this.attributes.length - 1 ][ 1 ] = "";
this.state = this.e_value;
} else
throw "Error - Unexpected end of string";
}
this.e_value = function( character ) {
if ( character == null )
throw "Error - Unexpected end of string";
else if ( character == '"' ) {
this.name = null;
this.state = this.e_wspace;
} else
this.attributes[ this.attributes.length - 1 ][ 1 ] += character;
}
this.e_parsed = function( character ) {
throw "Error - Unexpected character found after parsing is complete";
}
this.attributes = new Array();
// Transition from Constructor to e_wspace
this.name = null;
this.state = this.e_wspace;
// Go through characters feeding them one at a time with a final null
for ( var p = 0; p < string.length; ++p )
this.state( string.charAt( p ) );
this.state( null );
if ( this.state != this.e_parsed )
throw "Error - end state should be e_parsed";
}
return new Parser( toparse ).attributes;
}
With this implementation one nice side benefit is that the awkwardness of using enumerations in JavaScript is now neatly side-stepped.
Personally I find this version easier to work with, but many may consider the benefit to be marginal. To start to see the real benefit of this we need to see what happens when we want to extend the behaviour of the parser, but that will have to wait for a later article.
Instance behaviour in object-oriented languages
The characterisation between different object oriented systems is always to do with how messages are delivered to the method (i.e. the code that is to be executed). Normally, and for most purposes, we simply use the common member functions that object oriented languages provide us with for all of our needs, but there are times when it is better to remember the distinction between messages and methods so that we can choose when it is better to implement our own message delivery mechanisms and when we should use the language facilities available to us.
In this example we make use of the fact that JavaScript handles the member functions just like any other member and this allows us to change the function associated with a name just like we can change any data member. We can therefore use instance behaviour in order to change the code that is executed even though we repeatedly use the same name.
Normally we only associate this sort of change in behaviour with different types of object. Here I show that it can also be useful to do so for any given instance. In a later article I will show that this allows the class to be extended much more cleanly which makes this technique particularly suitable for use in libraries to write process skeletons.
Other languages
Exactly the same technique works in C++ which supports function pointers to methods. In C it can also be done by storing a function pointer in a structure. As ever in these two languages the function pointer syntax (especially the member function pointer syntax in C++) is somewhat confusing the first few times you see it.
The .NET environment also supports method pointers, but calls them “delegates”. I'm not familiar enough with the .NET programming environment to know how easy the technique is to use, but as the building blocks are there it shouldn't be too hard.
Java I fear is another matter entirely. One of the “simplifications” made in the language was to cut function pointers. This means that each state would have to be implemented as an instance of its a sub-class that implements a given interface. This probably makes the technique too verbose to use in practice1.
Sub-pages




© 2002-2025 Kirit & Tai Sælensminde. All forum posts are copyright their respective authors.
Licensed under a Creative Commons License. Non-commercial use is fine so long as you provide attribution.